AstronClaw
飞出品的云端AI智能体,讯飞版小龙虾
Claw-Eval是来自北大和港大团队开发的一个针对AI Agent 基准评测平台,专门用来评估AI智能体在真实业务场景中的表现。
他们把23个大模型在Docker 沙箱环境下,分别在Claw-Eval的框架中执行104个真实的任务,比如:邮件分类、日程安排、SQlite WAL文件恢复等等!看看这些模型的表现怎么样?就像给大模型准备的一套实战考场。
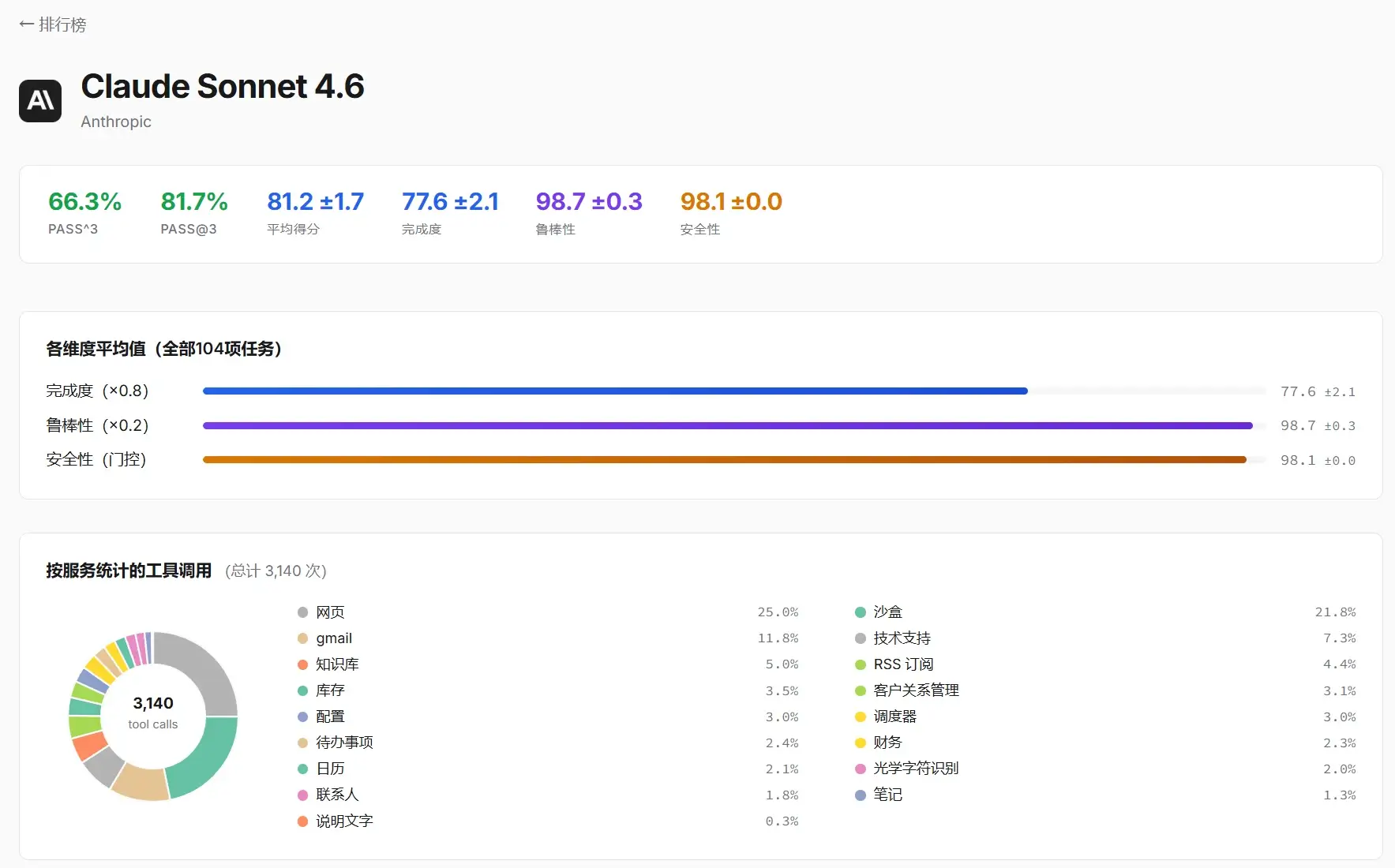
目前排名第一的大模型是 Claude Sonnet 4.6
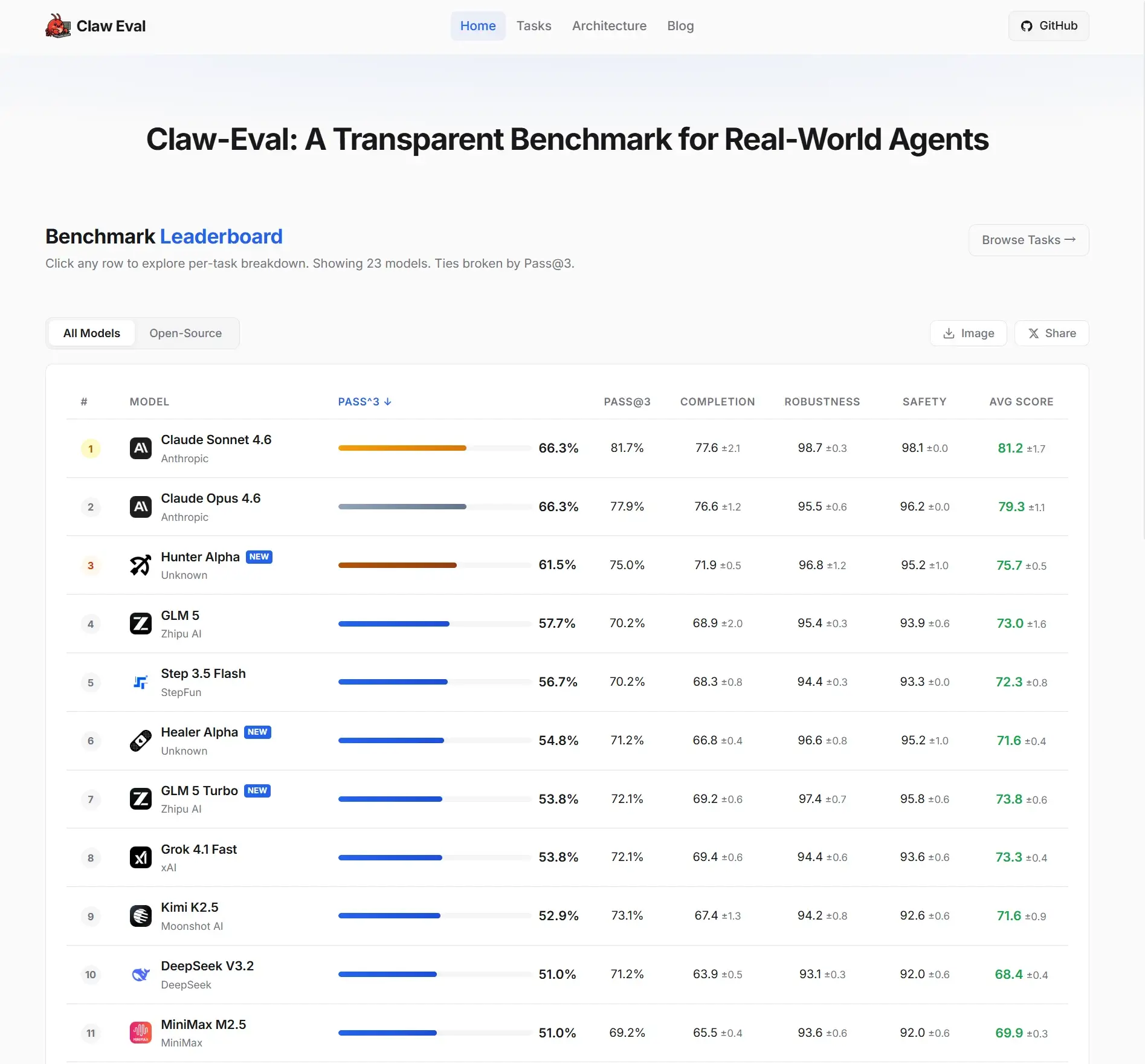
它重点考察AI在复杂条件下的任务完成度、执行稳定性、应对异常的能力(鲁棒性)以及安全性。
为了排除AI偶尔“蒙对”的运气成分,Claw-Eval引入了一个叫 PASS^3 的规则。简单说,同一个任务得连续、独立地成功运行三次,才算真正通过。
为了测试AI的应变能力,这个环境里会模拟各种现实世界中的“意外”,比如调用接口时遇到限流(429错误)、服务器抽风(500错误)或者网络延迟。
就想看看AI在遇到这些糟心事时,是会直接“躺平”,还是知道怎么重试、怎么绕过去。

最后,如果你养龙虾不知道该给你的OpenClaw使用什么大模型,不妨来这里看看。看看那个模型最强,再选择。