大语言模型的多层次多学科中文评估套件
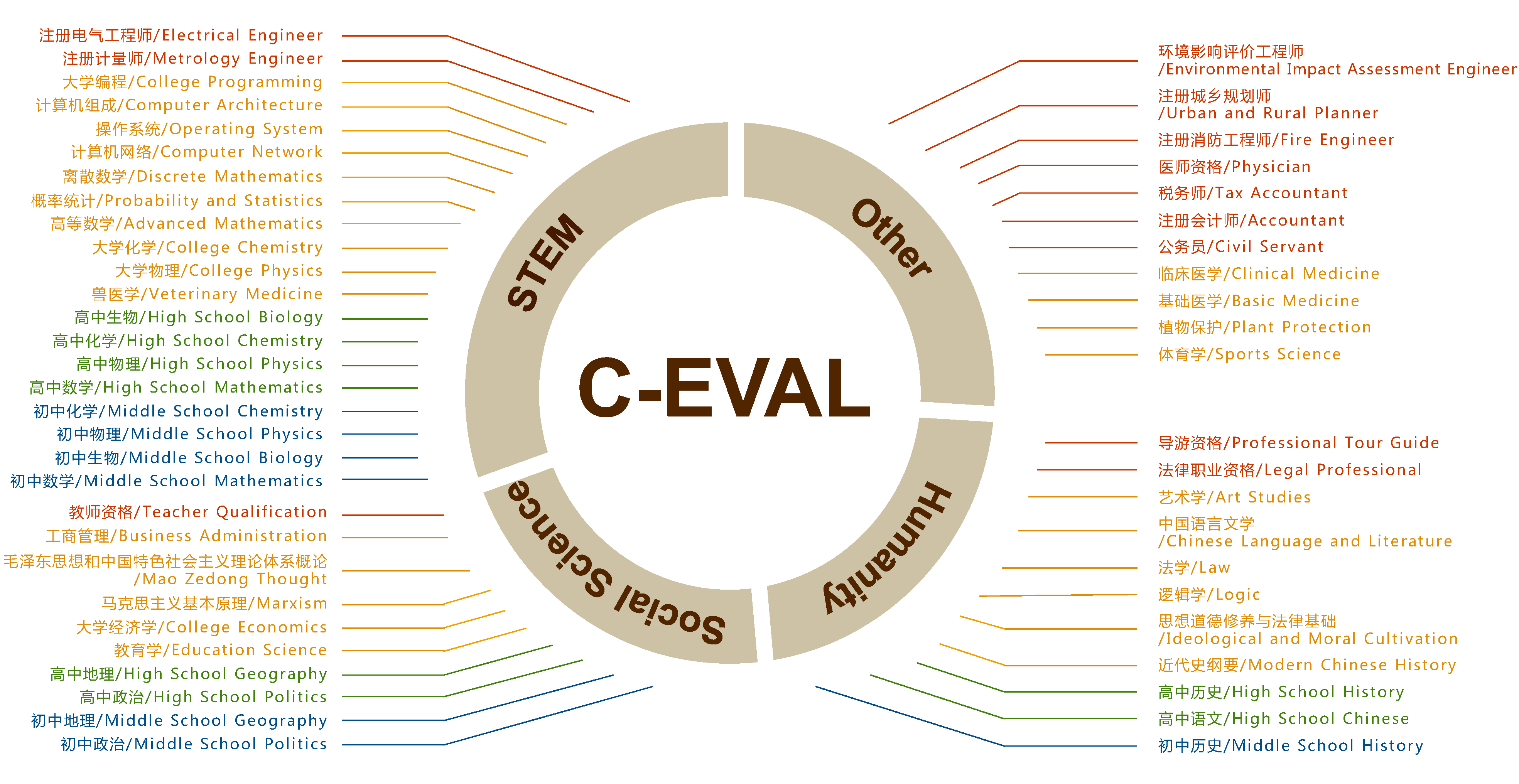
C-Eval 是一个全面的中文基础模型评估套件。它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,如下所示。
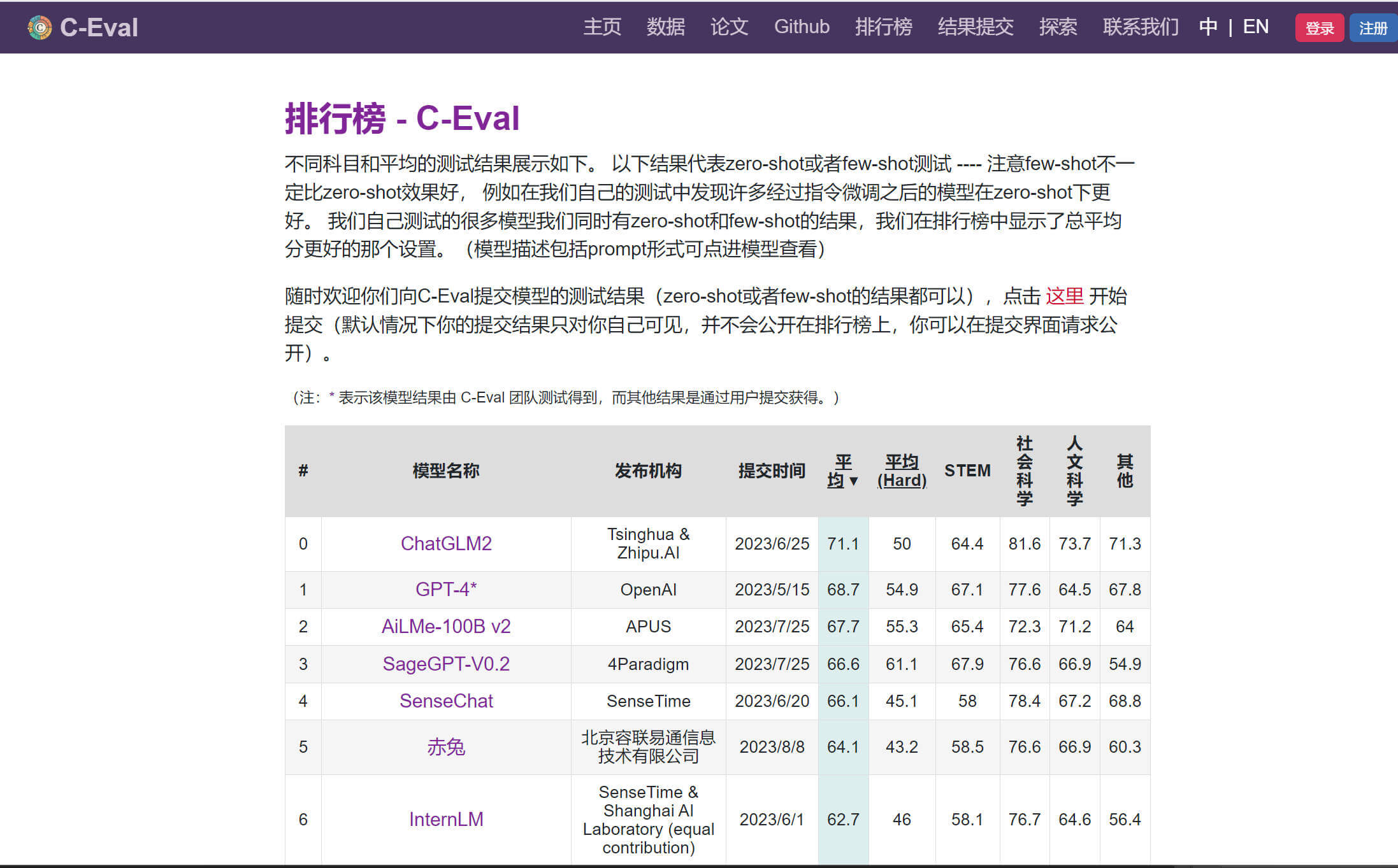
通过 C-Eval 试题的测试后得到了一份中文大语言模型的排行榜,其中表现最好的是来自 是由清华大学和智谱 AI 联合研发的第二代 GLM 系列对话语言模型,其次是GPT – 4模型。
Δ
Ctrl+D
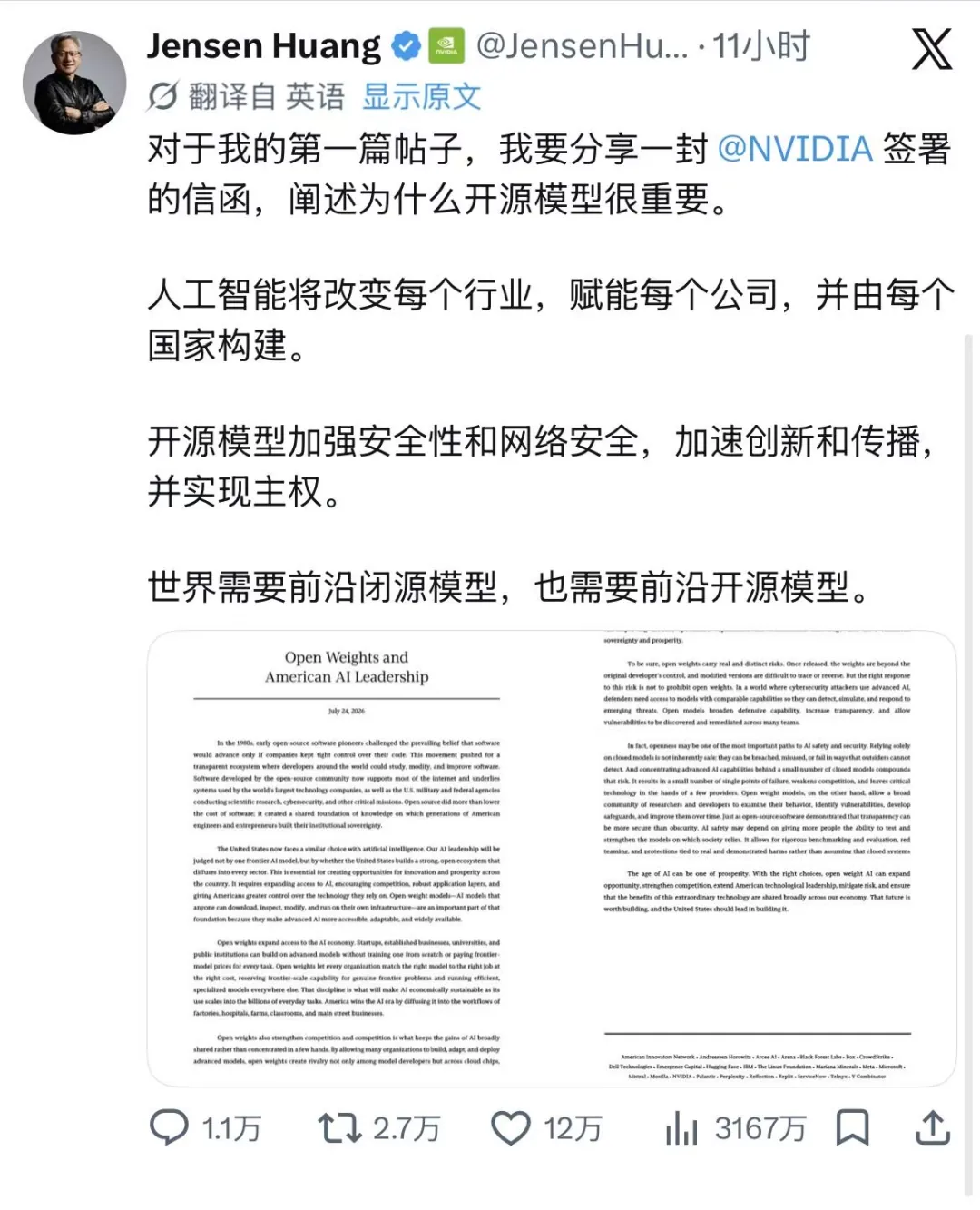
黄仁勋与马斯克的连续表态,反映美国科技界对开放权重模型及中国AI竞争力的政策分歧正在扩大。
就在刚刚OpenAI Codex 负责人@Tibo 发文称 暂时取消所有 Plus、Business 和 P
2026年7月8日,工业和信息化部网络安全威胁和漏洞信息共享平台(NVDB)发布《关于防范AI编程工具Cla
腾讯混元Hy3正式上线,WorkBuddy首发接入并限时两周免费体验,以任务解决率跃升至90%、耗时缩短34%及高性价比开源等亮点,重塑AI办公新标杆。
阿里巴巴内部今日下发通知,因近期 Claude Code 被曝存在植入后门的安全风险,经综合评估后将其列入高