Claw-Eval
针对AI Agent 基准评测平台,评估AI智能体在真实业务场景中的表现。
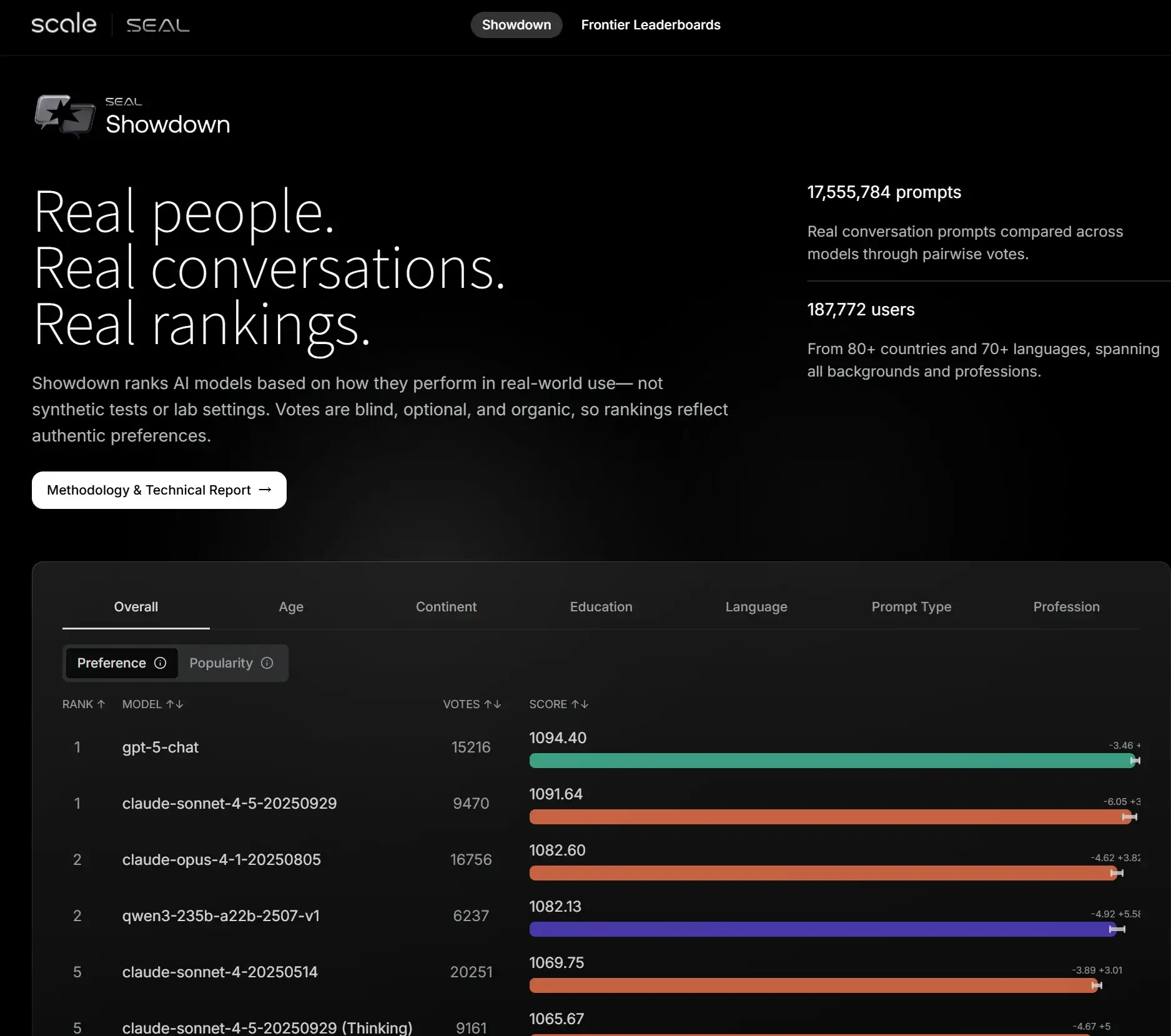
SEAL LLM 排行榜于2024年6月正式推出,是Scale AI为解决传统基准被“刷分”问题而开发的第三方评估系统。截至2025年12月,它已覆盖多个领域,包括编码、推理、多轮对话和代理工具使用等,定期更新以纳入最新前沿模型(如GPT-4o、Claude 3.5等)。排行榜使用私有数据集和人类专家评估,确保结果不可操纵,提供准确的模型性能洞察。最新更新中,Humanity’s Last Exam(HLE)基准已最终定稿为2500道难题,强调模型的校准误差和置信区间排名,推动AI社区向更可靠的评估标准转型。
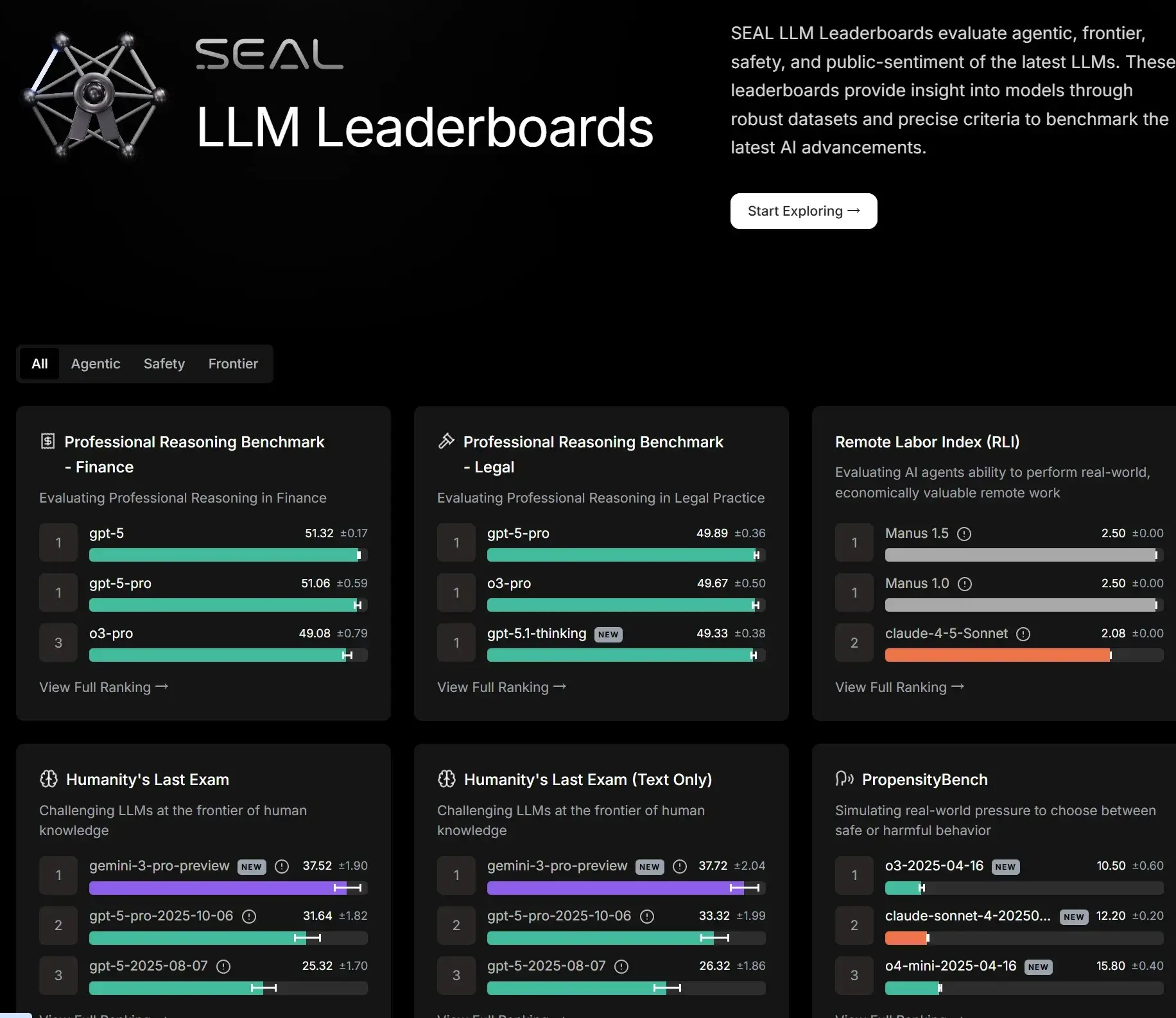
SEAL LLM 排行榜的核心功能是多维度模型排名和基准测试,主要包括: