新腾讯混元Hy3正式上线,WorkBuddy首发接入,限时两周免费体验!
距 4 月 23 日的 Hy3 preview 发布已经过去了两个半月,今天(7 月 6 日)腾讯混元 Hy3 正式版终于发布,WorkBuddy 作为首发接入平台同步开启为期两周的限时免费体验。元宝也同步接入且免费开放。 Hy3是一个快慢...
腾讯云最近开源了一个叫 TencentDB-Agent-Memory 的工具,专门解决 AI Agent 跑长任务时上下文膨胀、Token 疯涨和模型“犯糊涂”的问题。对于经常让 Agent 连续调用十几次工具的开发者来说,中间产物堆满上下文导致又贵又容易出错,这个工具算是针对痛点来的。

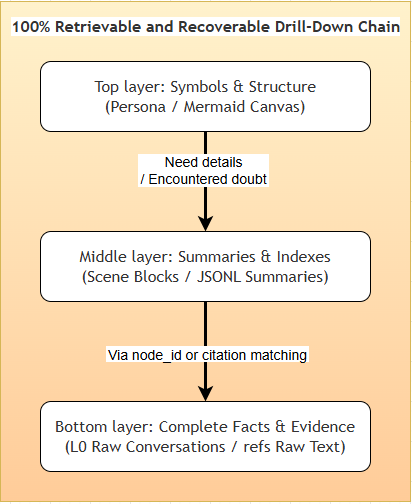
核心机制之一是上下文卸载。传统做法把网页抓取、代码执行等冗长结果全塞上下文,而 Agent Memory 会把完整结果存到外部文件,上下文只留一行摘要和索引路径。它设计了四级结构:L0 原文、L1 结构化 JSONL、L2 自然语言摘要、L3 Mermaid 节点标签。Agent 日常只看轻量的 L2 和 L3,需要细节时再通过 node_id 逐层回溯。这种设计保证了压缩不是黑盒,原始数据随时可查证。
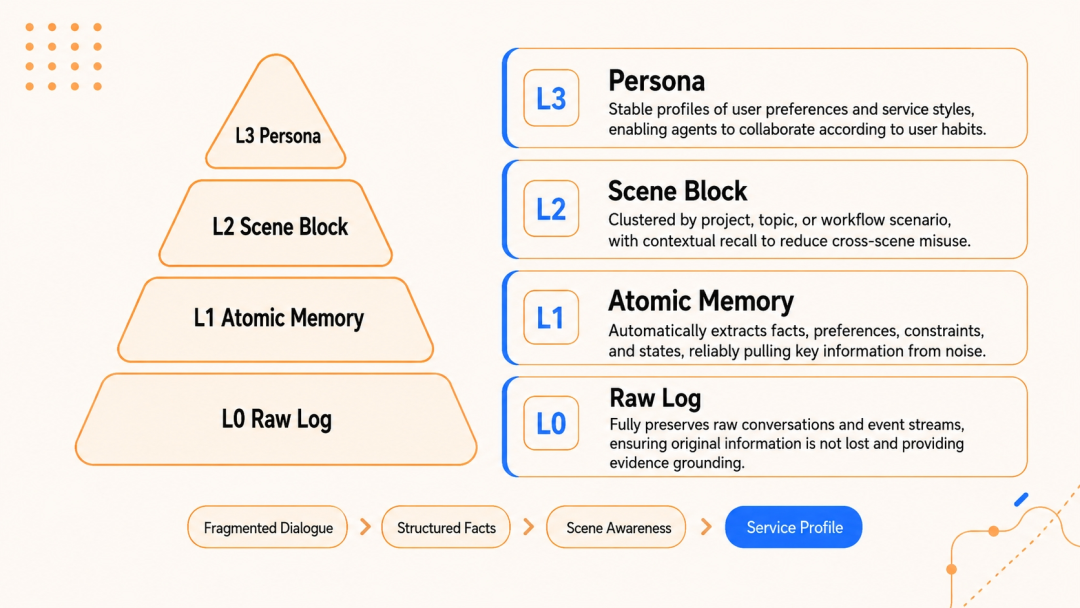
另一个机制是用 Mermaid 流程图把线性聊天记录变成可导航的依赖图。做完的、正在做和没开始的节点状态一目了然。Agent 不用回头翻历史记录就能看清全局,大幅减少了因迷失方向导致的重复查询和无效分支。
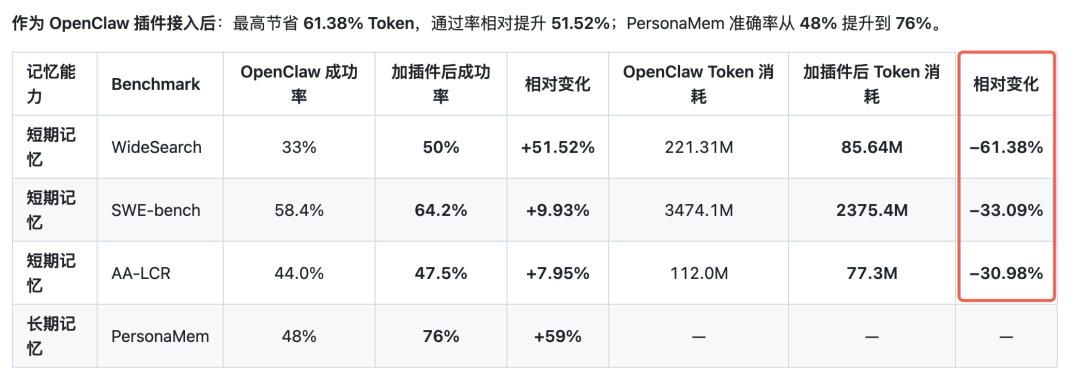
官方在多任务连续 Session 实验中给出数据:最高降低 61.38% 的 Token 消耗,任务通过率相对提升 51.52%。Token 省了,成功率反而升了,本质上是因为上下文噪声少了,模型注意力更集中。
目前项目在 GitHub 已有 3.9k Star,默认用本地 SQLite 存储,零外部 API 依赖。不过 Issues 里有开发者反馈搭配 DeepSeek 等模型时偶有 L1 提取失败或兼容性问题,想上生产环境的话建议先跑跑测试。
怎么用
相关链接
图片来源:mp.weixin.qq.com