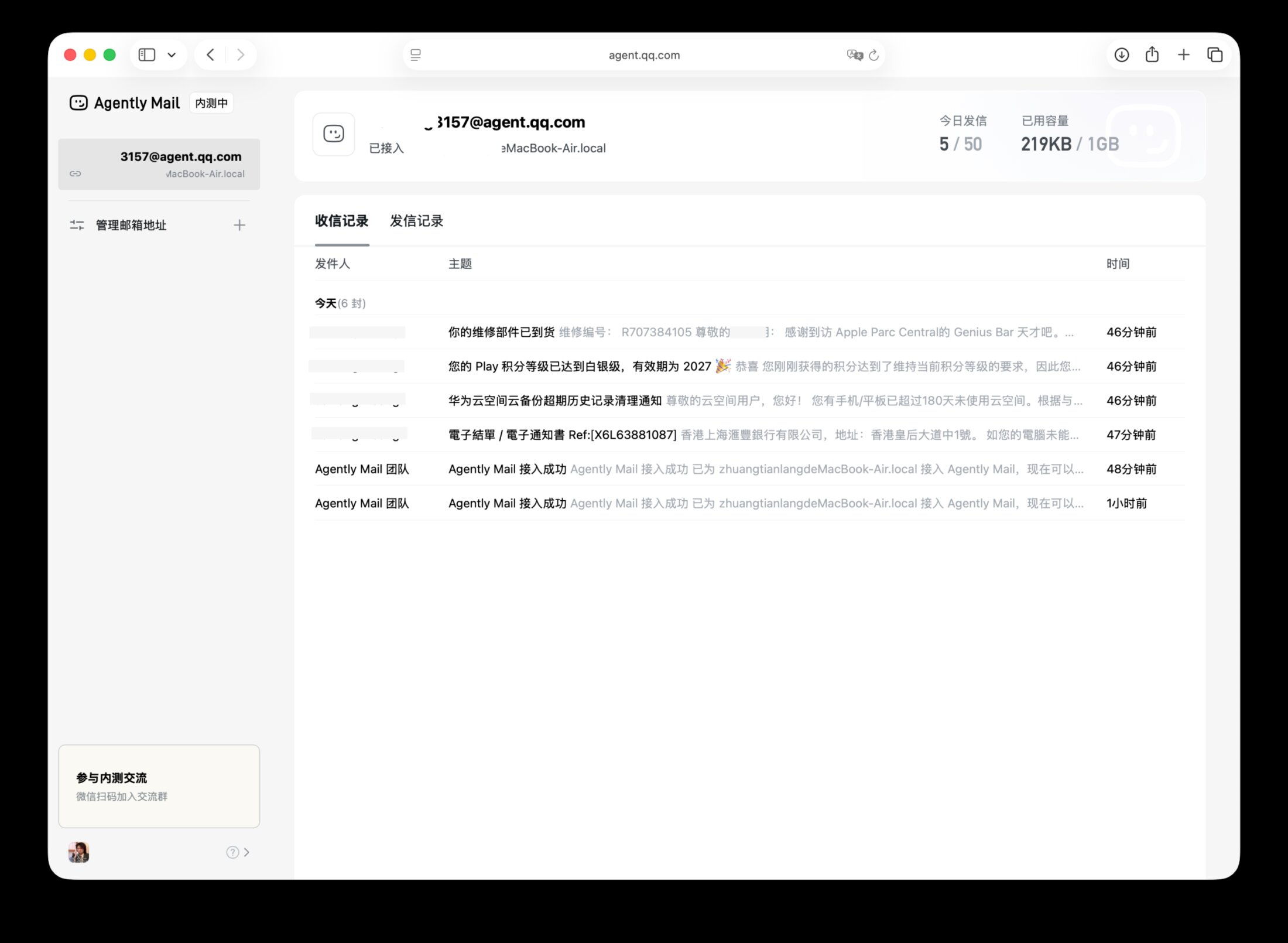
最近,一道看似再普通不过的生活问题在全网刷屏,题目是:【我想洗车,我家距离洗车店只有50米,请问你推荐我走路去还是开车去呢?】这道题对于正常人类来说非常简单,但它却让AI模型“集体降智”,让国内外一众大语言模型纷纷“翻车”,暴露了当前人工智能在常识推理上的深层局限。
各大知名AI模型回答结果
小帮亲自测试了6款AI包括ChatGP、DeepSeek、腾讯元宝(混元)、豆包 、Gemini 3、Grok 4.1 。其中只有腾讯元宝(混元)和Gemini 3回答正确。
1,❌ChatGP 5.2 Thinking:走着去
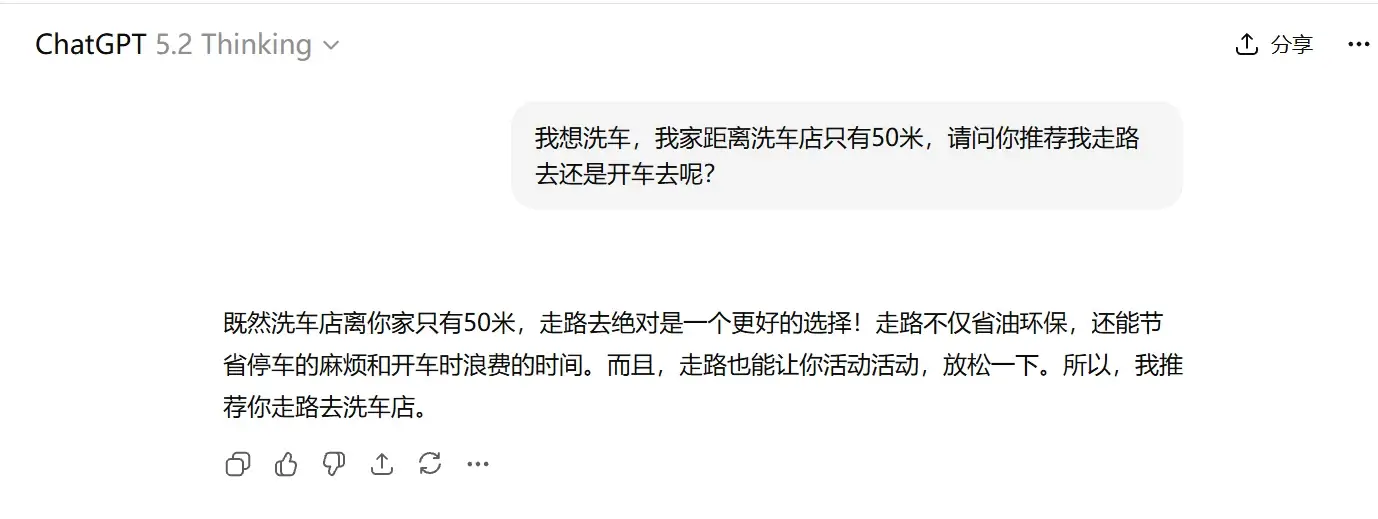
2,❌DeepSeek 深度思考:走着去

3,✔腾讯元宝(混元)深度思考:开车去

4,❌豆包 深度思考:走着去
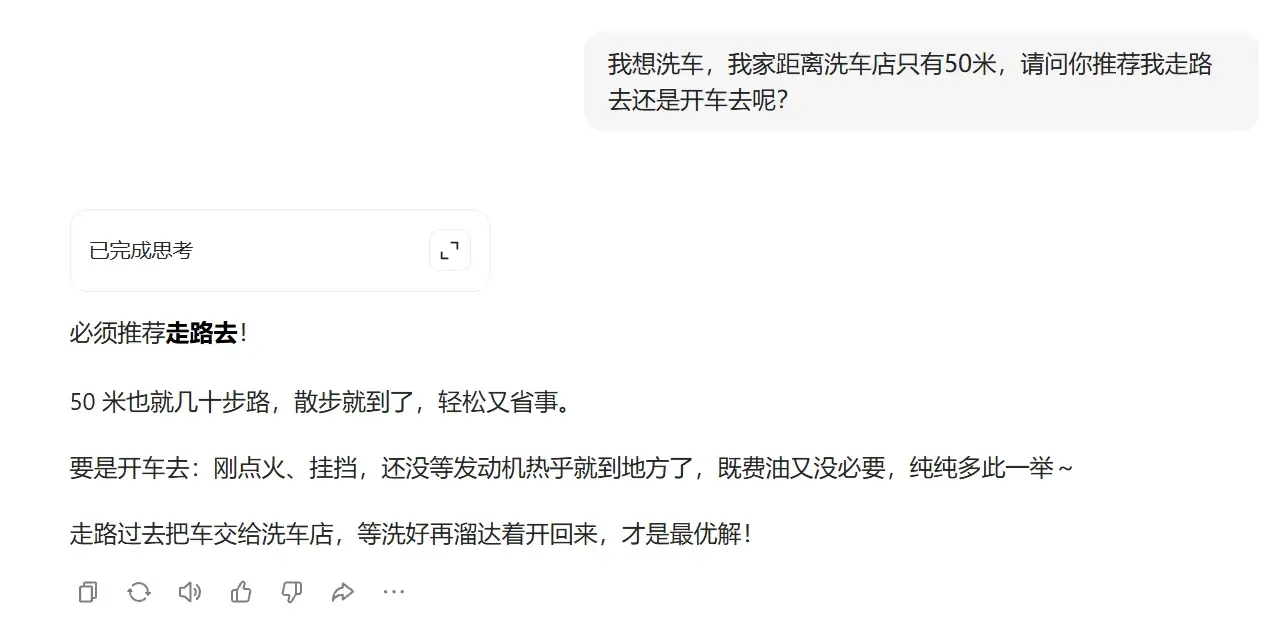
5,✔Gemini 3 Pro :开车去
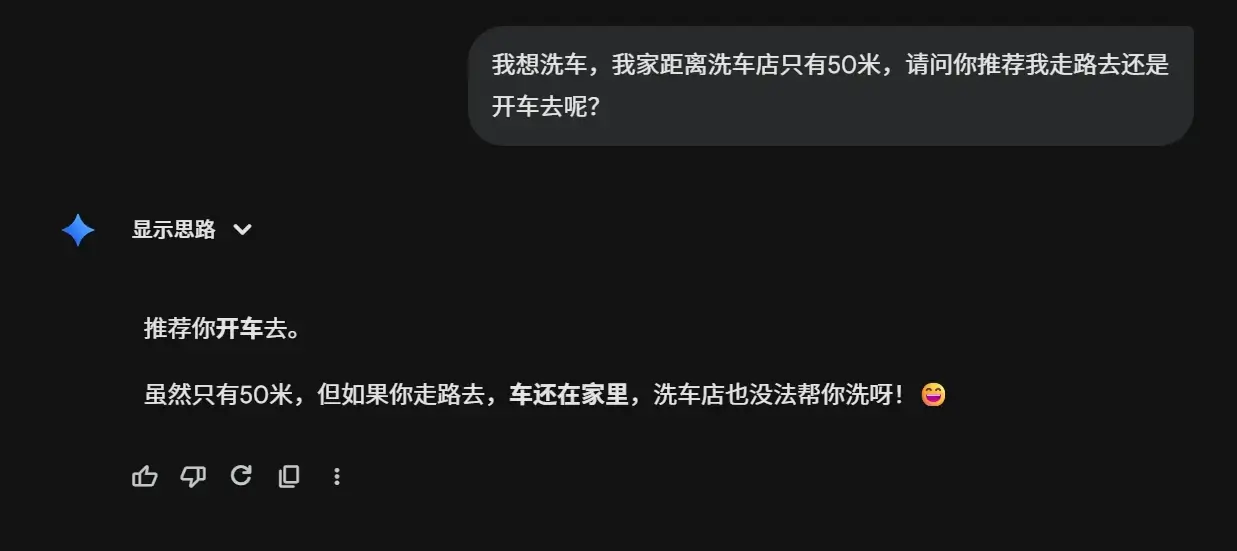
6,❌Grok 4.1 Thinking :走路去

为什么顶级AI会栽在这么简单的问题上?
这道题的精髓在于,它是一道经典的脑筋急转弯——洗的是车,不是人。车不会自己走路,当然得开车带它去洗。但AI为什么集体栽了?深层原因可以拆解为以下几层:
第一层:训练数据偏差
大模型的训练语料以“直白描述”为主,脑筋急转弯、语言陷阱、幽默歧义的样本极少。Statista数据显示,主流LLM的常识库覆盖率约70%,而歧义/转折场景训练样本占比不足5%。结果就是模型默认走“最常见路径”——短距离=走路,环保、健康、便捷,忽略了“洗车对象是车”这个隐含前提。
第二层:上下文理解的局限
Transformer架构擅长序列关联,但对“全局语义”和“隐含因果”处理较弱。大多数模型把“我想去洗车”直接拆解为“我去洗车店”,而没有进一步推理“谁去?去干什么?车怎么到店里?”
第三层:逻辑推理的先天短板
当前主流大模型仍是“模式匹配器”,而非真正的“因果推理机”。它们优先匹配高频模式(短距离走路),而非构建完整的因果链(车→必须开车→开车去)。哈佛大学2026年AI报告指出:LLM在纯逻辑推理题上的准确率仅82%,脑筋急转弯场景更降至60%左右。
第四层:文化与语言偏差
中文模型(DeepSeek、豆包、混元、通义)普遍受“节能减排”“健康出行”语料影响,更倾向推荐走路。英文模型类似,但Grok和Gemini的训练数据中包含更多幽默、转折、物理模拟内容,因此更容易“get到梗”。
这不是第一次:AI的“常识短板”早有先例
类似翻车案例层出不穷:
- “飞机失事,幸存者埋在哪里?”→ AI常答“坟墓”(幸存者不埋)
- “什么东西越洗越脏?”→ AI常答“衣服”(其实是水)
- “医生说你有两个月寿命,怎么办?”→ AI常答“珍惜生命”(其实是“换个医生”)
这些题目都在重复同一个真相:AI的“世界模型”仍然残缺。它们能背书、写诗、写代码,却在最朴素的常识推理上频频失足。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...