
DeepSeek 开源 DSpark 投机解码框架,加速 DeepSeek-V4 生成速度 60-85%
DeepSeek 发布 DSpark 投机解码框架并开源检查点与训练代码。该框架不是新模型,而是在 DeepSeek-V4 权重上附加草稿模块,通过半自回归生成(并行骨干 + 轻量级顺序头)实现无损加速。生产环境下,DeepSeek-V4...
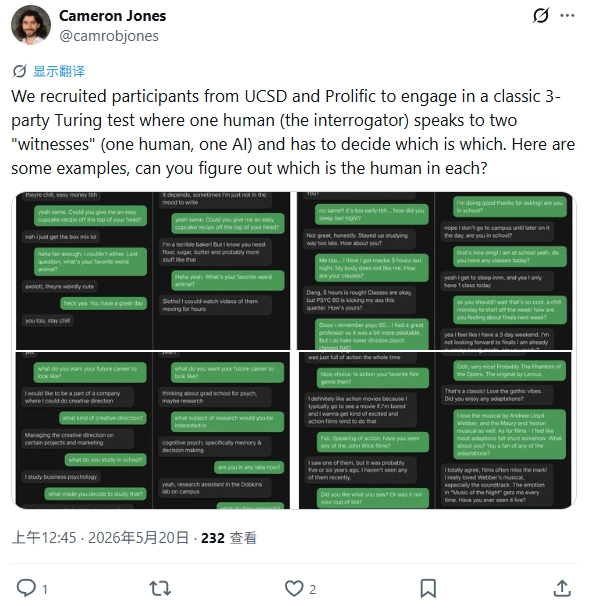
加州大学圣地亚哥分校的一项新研究,为经典的图灵测试提供了针对现代大语言模型的实证数据。研究称,在获得特定提示后,GPT-4.5在5到15分钟的文本对话中,被73%的“裁判”判定为人类,该比例显著高于与其对比的真实人类参与者。
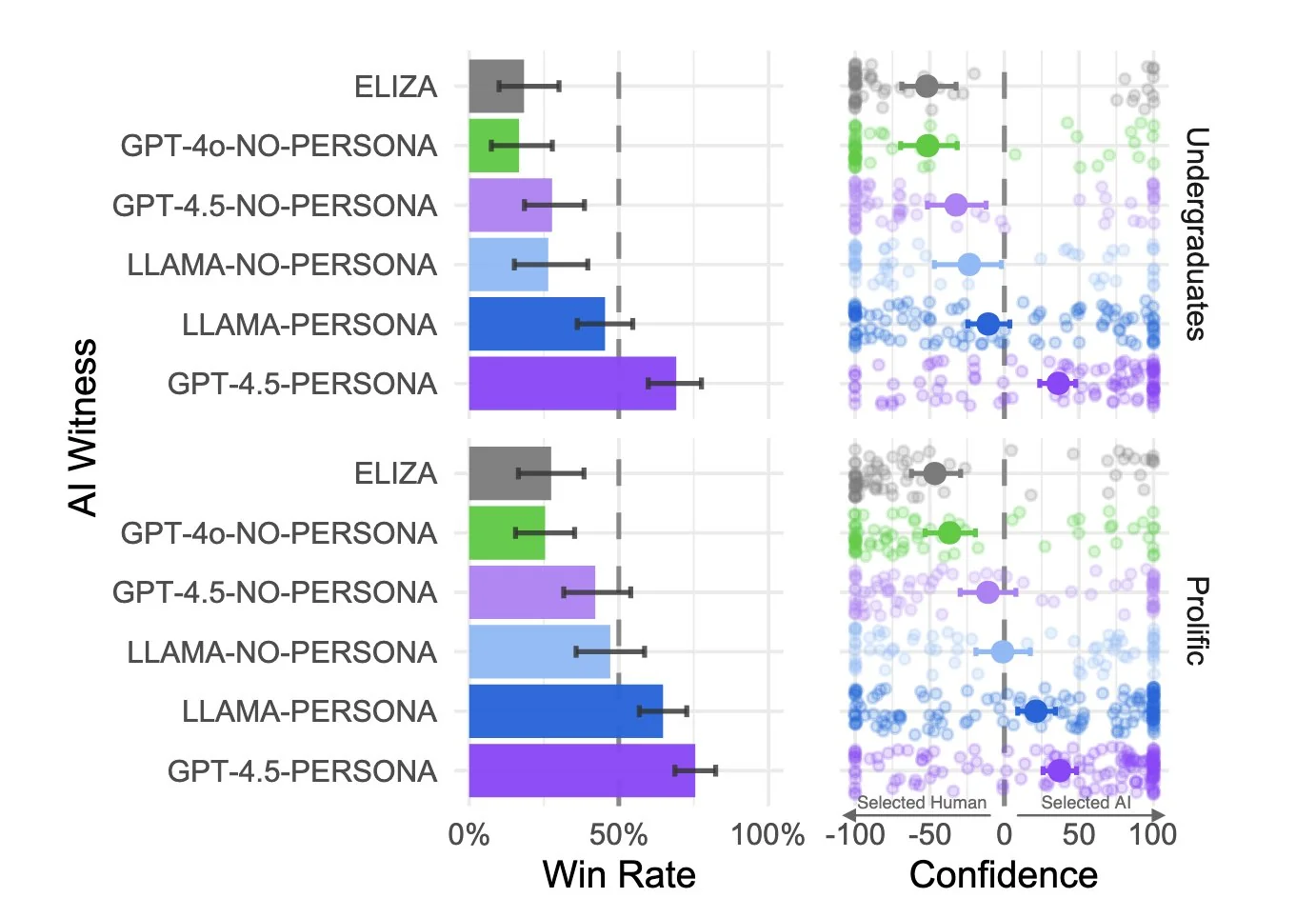
实验设置了多个对比组:LLaMa-3.1-405B被判定为人的概率是56%,与真人统计学上无差异;而GPT-4o和早期规则机器人ELIZA的判定率均低于25%。研究于2026年5月22日发表在《美国国家科学院院刊》上。

研究的通讯作者指出,模型并非靠展示知识深度取胜,而是通过模仿人类的社会行为特征,如直接的语气、幽默感甚至易错性。但这一切都高度依赖于提示词。在没有特定提示的情况下,GPT-4.5被误认为人的概率骤降至36%。这说明模型“有能力表现得像人,但可能不具备自行揣摩如何表现得像人的能力”。

研究团队认为,相对容易让这些模型变得与人类难以区分,这意味着当人们在线上与陌生人互动时,需要降低对“对方是真人”的确定性信心。论文作者更直接指出,图灵测试对模型而言“本质上是一场关于说谎的游戏”,这带来了关于欺诈、虚假信息传播等更深层的风险担忧。
这项研究并未提供可直接使用的产品或API,它更像一次面向AI能力边界和安全影响的学术实验。不过,它无疑给所有AI从业者和使用者提了个醒:在拟人化交互成为常态的当下,辨别对话对象的真伪,或许会变得更困难也更重要。
图片来源:IT之家(RSS)





