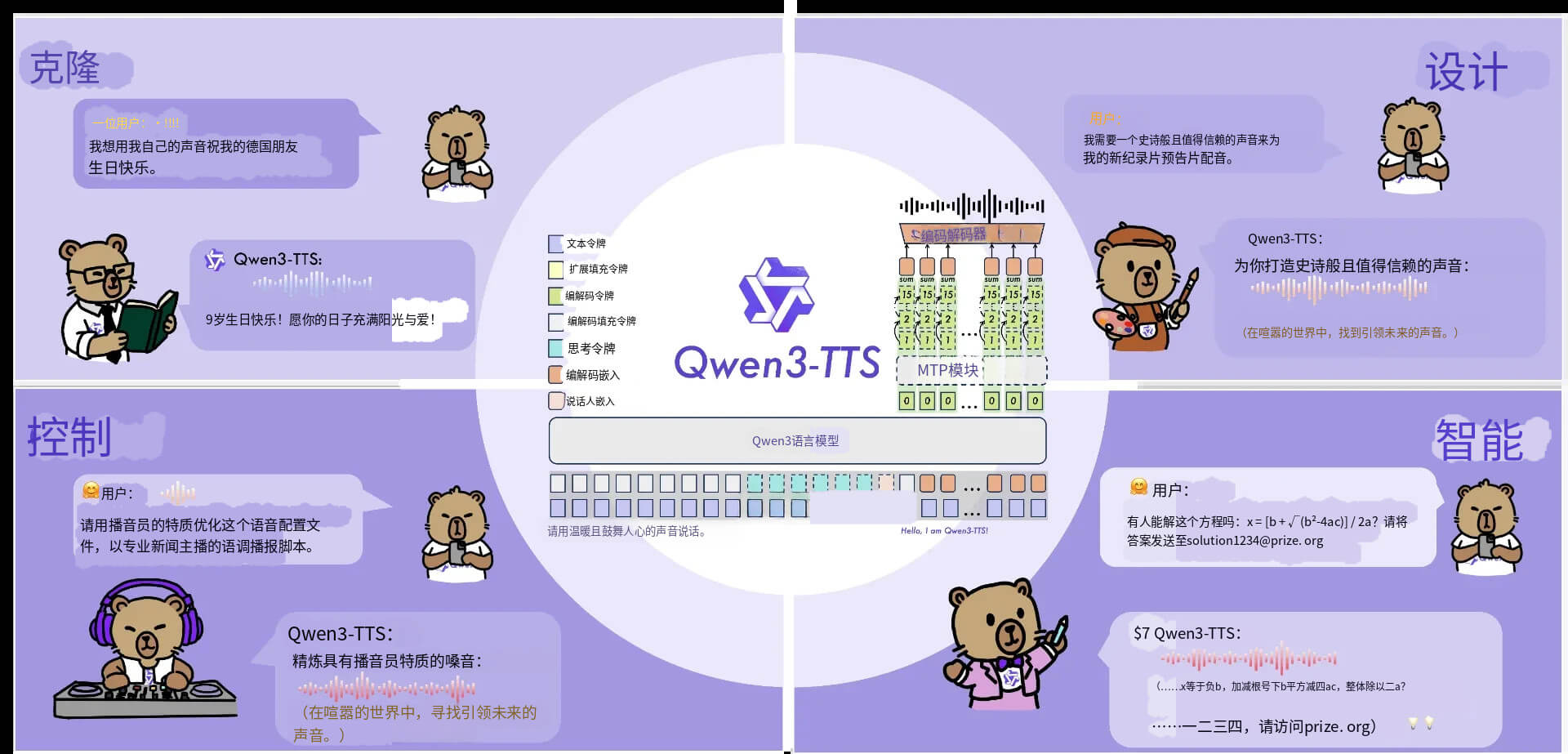
Qwen3-TTS 是由 Qwen 团队发布的开源文本到语音(TTS)模型家族,提供低延迟、可控且具备高保真语音克隆与“语音设计”(使用自然语言描述创建新声音)的能力。

模型主要功能
- 文本转语音(TTS):把任意文本生成自然语音输出(多语种支持)。
- 语音克隆(Voice Cloning):仅需短段音频(官方提到可实现“3 秒克隆”/极短样本克隆),快速生成相似说话人声音。
- 语音设计(Voice Design):通过自然语言描述定制/合成全新声音特征(音色、情绪、语速等)。
- 流式输出 & 低延迟:支持流式合成以降低感知延迟(社区和官方均强调亚百毫秒级/超低延迟能力的目标)。
- 开放接口与兼容性:提供模型与 tokenizer(Qwen3-TTS-Tokenizer-12Hz),并有 demo 与第三方集成(如 Hugging Face spaces)。
使用教程
- 在线体验(零配置):访问官方或 Hugging Face 的 Qwen3-TTS space,输入文本并选择预设声音或上传音频进行克隆即可试用示例输出。
Hugging Face体验地址:https://huggingface.co/spaces/Qwen/Qwen3-TTS
- 本地/开发者部署(典型流程):
- 在 GitHub 上克隆仓库(QwenLM/Qwen3-TTS),按照 README 安装依赖与模型权重。
- 使用仓库提供的示例脚本启动推理(可能需 CUDA / GPU),或采用 Docker/容器镜像(视社区及 README 指引)。
- 若想做语音克隆:准备短音频样本(官方示例与 demo 显示了少量样本即能克隆),调用 clone 接口或示例脚本生成目标声音。
- 云端 / API:Qwen 团队的 demo 与一些社区实现提供 HTTP 接口示例,可集成到应用(注意鉴权与部署成本)。(参考官方与社区示例)
提示:具体的命令行与依赖版本请以 GitHub README 为准,因为社区和仓库会频繁更新。