
OpenAI 于 2025 年 12 月 11 日(OpenAI十周年的日子)正式发布 GPT-5.2,这是其 GPT-5 系列的最新迭代版本,被定位为“专业知识工作领域最强大的模型系列”。
并且在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升!
距离上次GPT-5.1的发布仅仅过去1月的时间,之所以这么快的发布主要是为了应对谷歌 Gemini 3 的强力竞争,OpenAI 内部甚至一度进入“红色警戒(Code Red)”状态来加速迭代。
版本细分
这次 GPT-5.2 拆分了Instant、Thinking 和 Pro 三种变体,针对不同场景优化速度、深度和准确性。
GPT-5.2 Instant(即时版):
- 定位: 高速、低延迟,适合日常对话、快速信息检索、翻译和简单写作。
- 升级点: 取代了之前的 GPT-5.1 Instant,响应更敏捷,且保持了更自然的对话语气。
GPT-5.2 Thinking(思考版):
- 定位: 专为复杂任务设计,如编程、数学、长文档分析、电子表格处理。
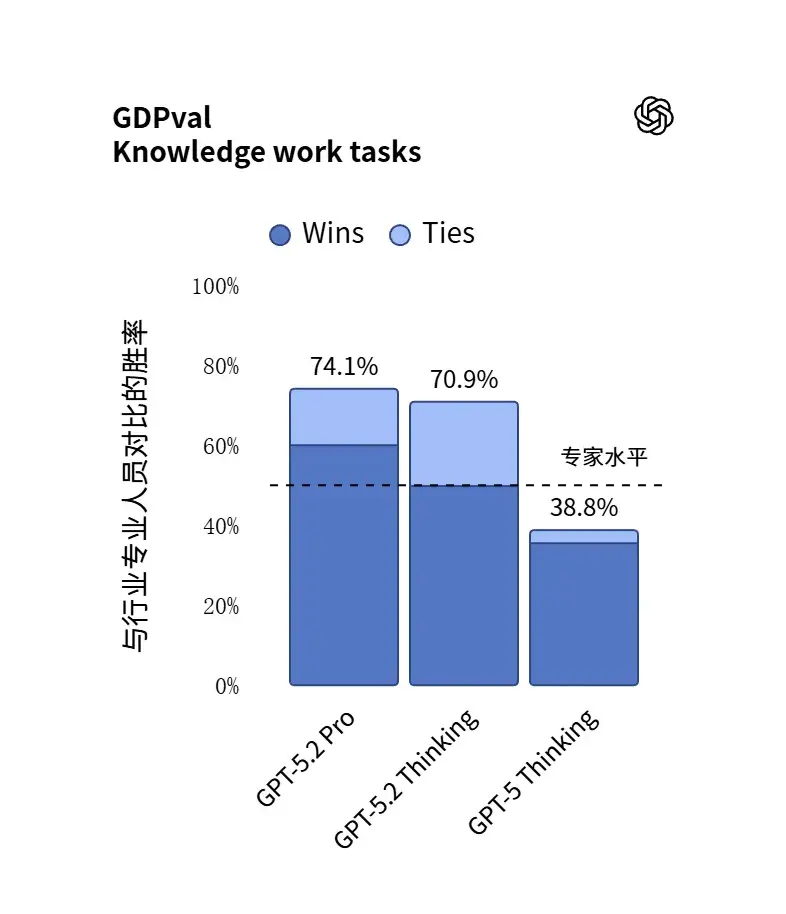
- 升级点: 在逻辑推理和多步任务执行上显著增强,官方宣称其在“GDPval(知识工作评估)”中击败或持平了 70.9% 的人类专家。
GPT-5.2 Pro(专业版):
- 定位: 最顶级的模型,用于处理最棘手的问题,追求极致的准确性和可靠性。
- 特点: 相比其他版本,它在回答前会进行更深度的思考,错误率最低。
GPT-5.2 Thinking 变体在 OpenAI 新推出的 GDPval 基准(覆盖 44 种职业的真实工作任务,如法律简报、工程蓝图、护理计划)中得分 70.9%,首次达到或超过人类专家水平,较 GPT-5 的 38.8% 提升近 83%。
下图左侧是GPT‑5.2 Thinking生成的表格,右侧是GPT‑5.2 Thinking 生成的电子表格,在复杂度与格式呈现上GPT‑5.2都有明显提升。

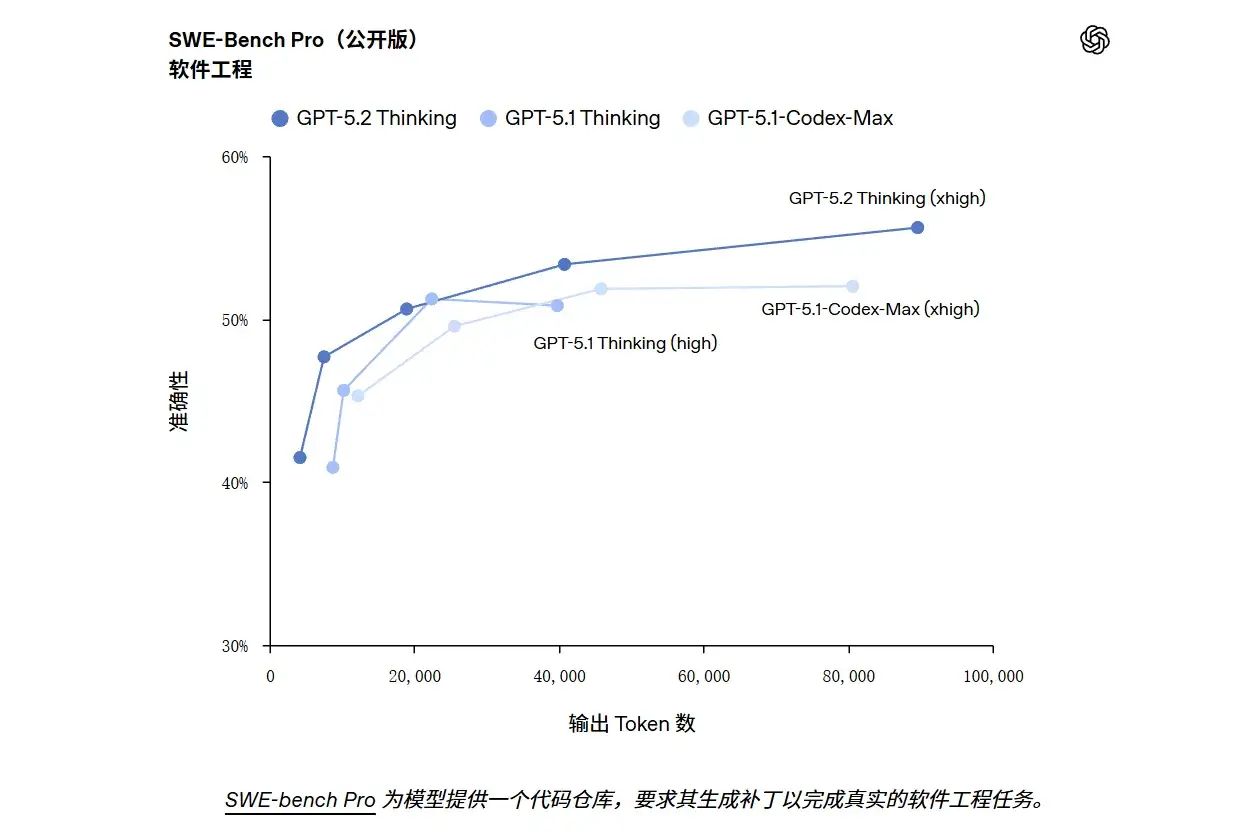
GPT‑5.2 Thinking 在 SWE-bench Pro 测试取得了 55.6% 的新成绩。SWE-bench Pro 是一项严格评估真实软件工程能力的基准测试。
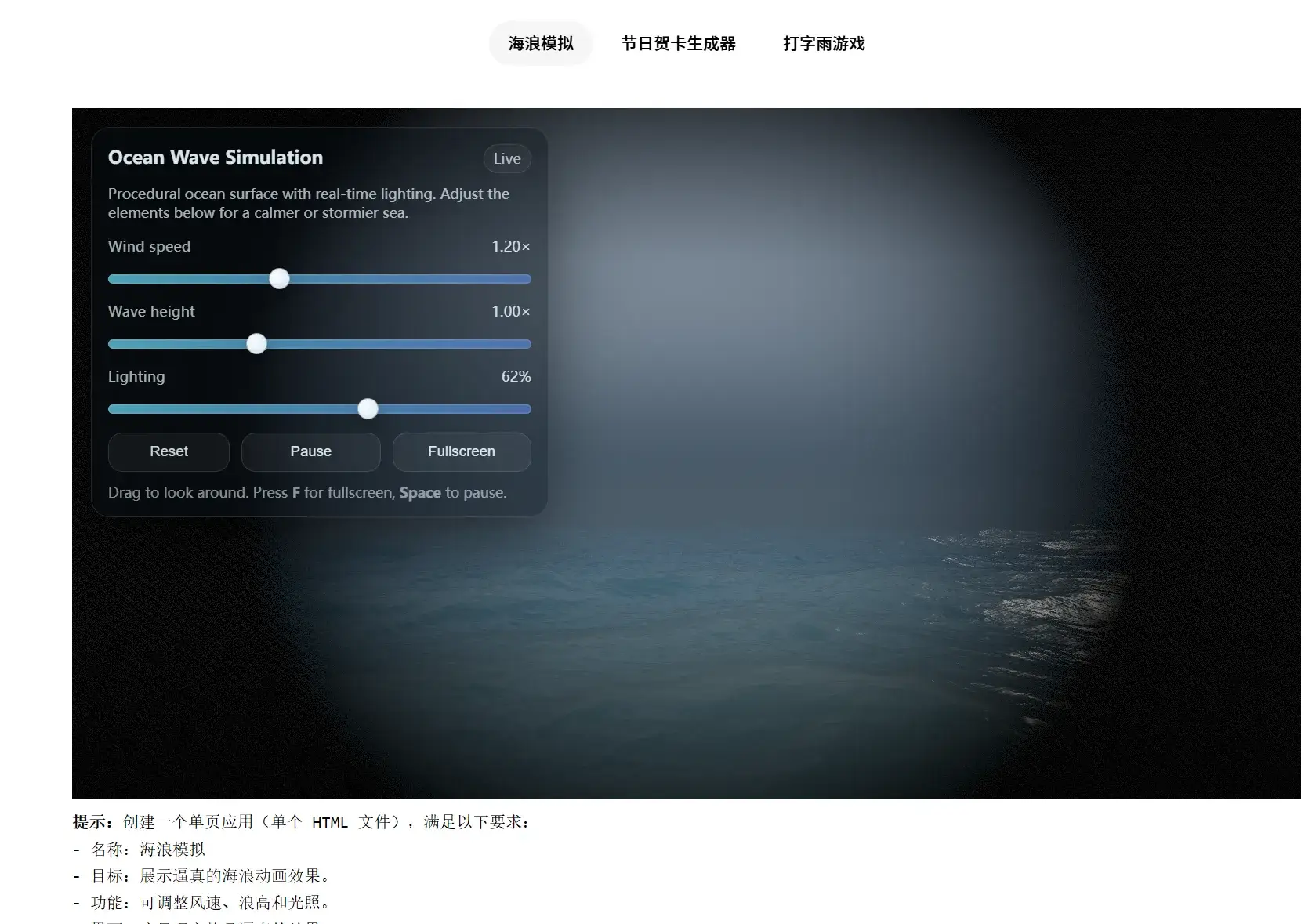
下图是用GPT‑5.2 Thinking生成的海浪模拟器前端工程,足以代表了自 GPT-5 以来在智能体编码上的最大飞跃。
视觉理解能力也大幅提升,图表/GUI 理解错误率降低 38%,支持图像感知、空间推理和跨模态任务。如下图中所示:GPT-5.2能准确标记出更多主板上的元件

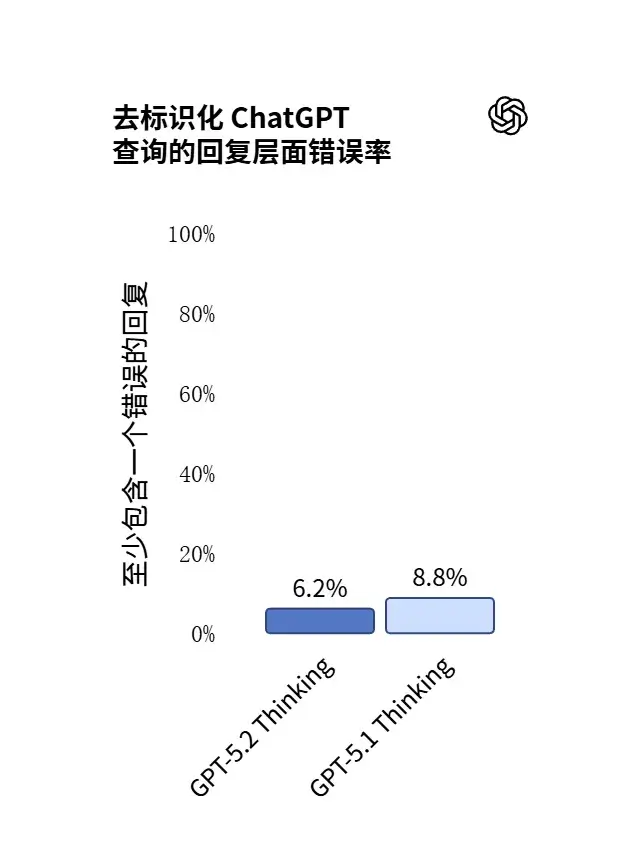
幻觉减少与可靠性提升:在一组去标识化的查询测试中,GPT-5.2 Thinking包含错误回答的情况相比GPT-5.1减少了30%,这在专业研究和决策支持中至关重要。
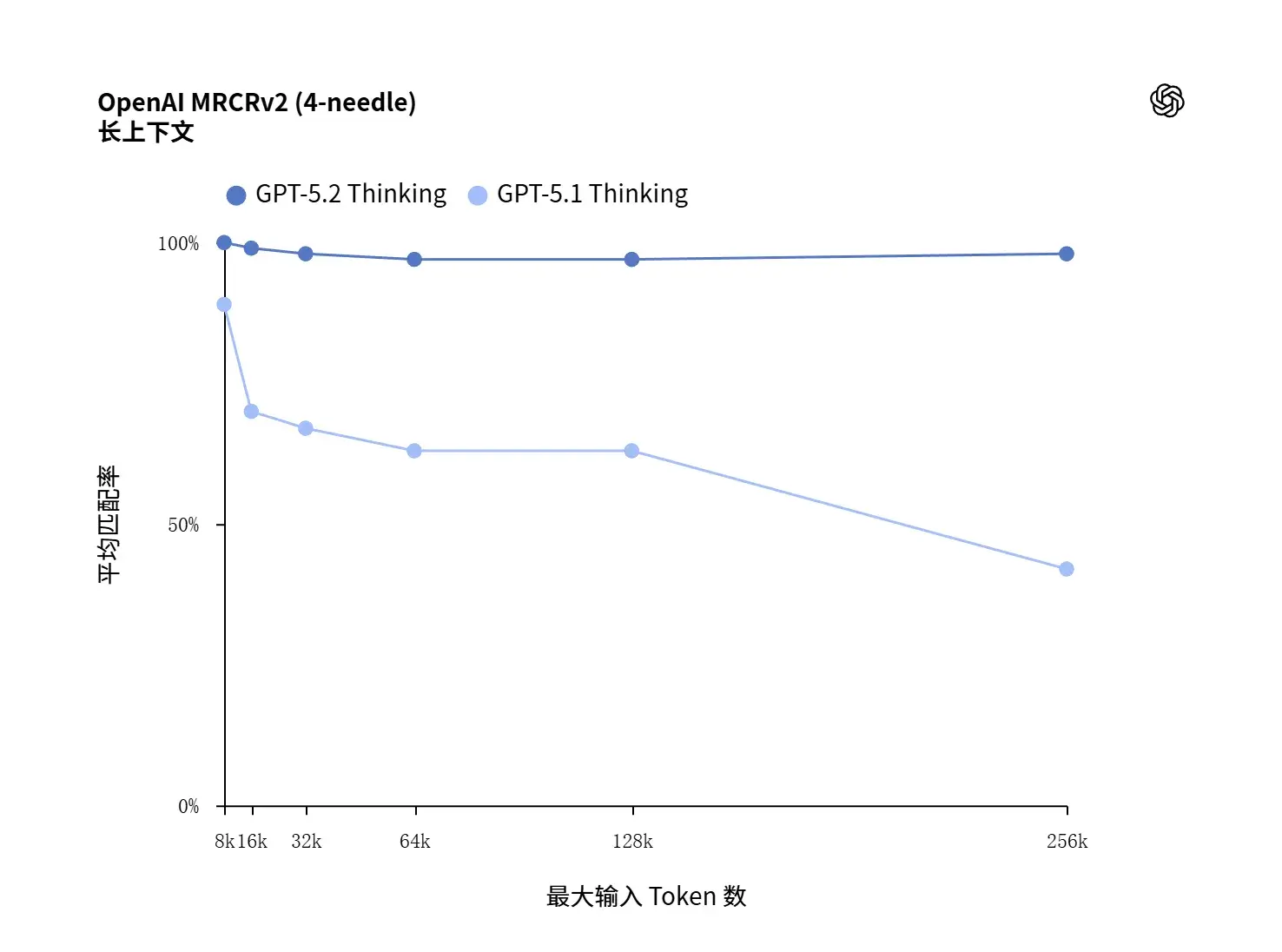
长上下文准确率近 100%(MRCRv2 “needle in haystack” 测试,达 256k tokens),适用于长报告、合同和多文件项目分析。
以上就是GPT‑5.2 的主要升级内容。总体而言,GPT‑5.2 在通用智能、长上下文理解、智能体工具调用以及视觉方面都有显著提升,使其在端到端执行复杂的真实任务时,比以往任何模型都更为出色。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...








