
近日,DeepSeek-AI团队开源了令人瞩目的DeepSeek-OCR模型,这项被称为“上下文光学压缩”的创新技术,有望彻底改变大语言模型处理长文本的方式。
当前,所有大语言模型在处理长文本时都面临一个根本性困境:计算复杂度随文本长度呈平方级增长。序列越长,消耗的算力资源呈指数级增加。就在其他厂商专注于不断拉长上下文窗口时,DeepSeek团队另辟蹊径,选择了做减法的道路

虽然名字里有“OCR”(光学字符识别),但它的核心理念是”视觉模态压缩长文本”。
既然一张图像能包含大量文字信息,而且使用的Token数量远少于等效文本,何不将文本转换为图像进行压缩?这就是所谓的 “视觉模态压缩长文本”
一图胜千言,在AI长文本处理领域有了全新的诠释
DeepSeek-OCR 就是将长文本(例如一整页文档)先转化为高分辨率的图像,然后通过一个高效的视觉编码器将其压缩成少量、信息密集的视觉 Token,最后再由一个语言模型解码器从这些视觉 Token 中重建出原始文本。
这种思路从根本上解决了大型语言模型(LLM)在处理超长文档时面临的上下文长度和计算效率瓶颈。
从下图可以看出,DeepSeek-OCR 大模型用最少的Token获得了很高的性能!
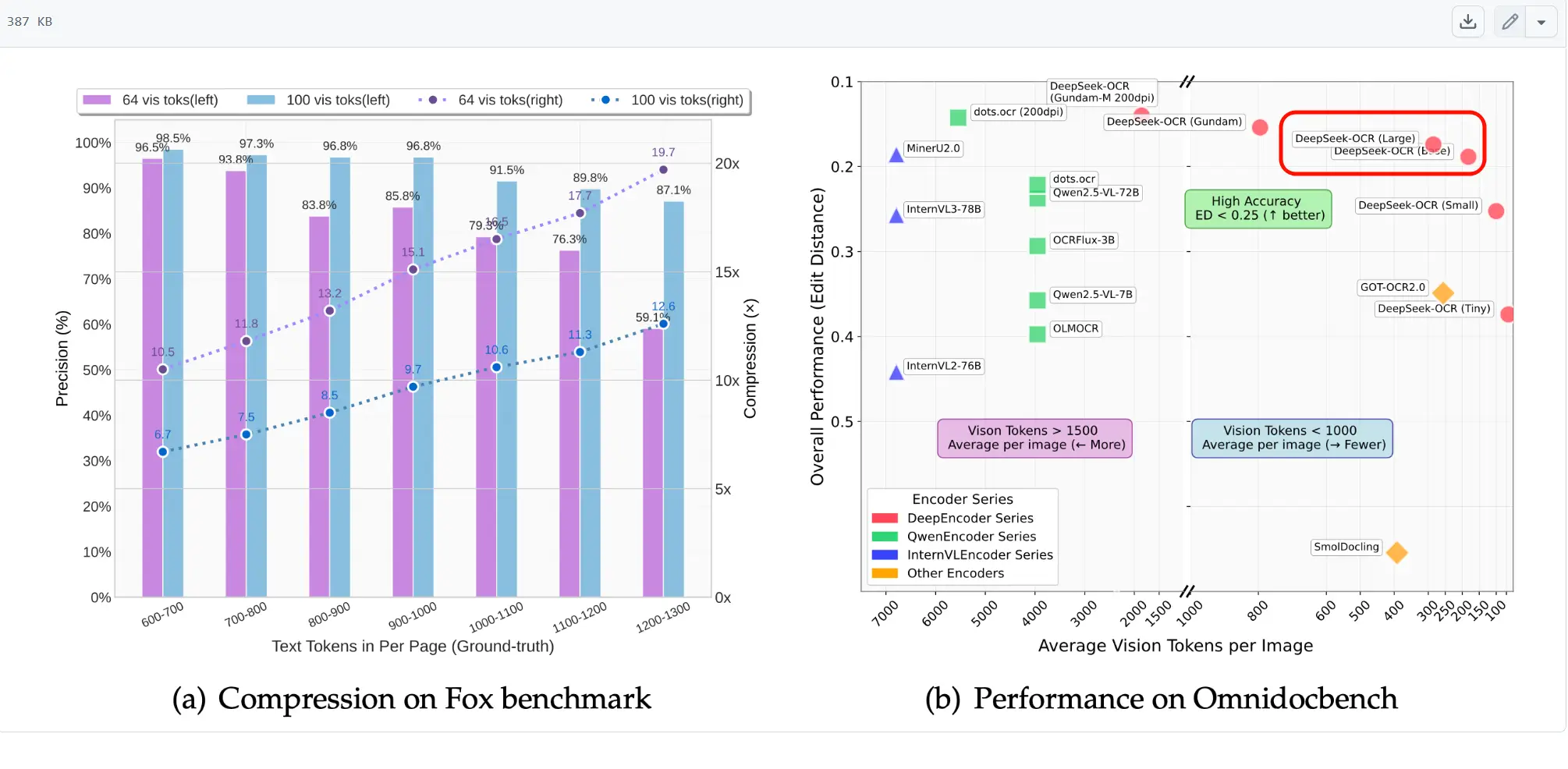
用通俗的语言来说DeepSeek-OCR“别一字一句地死记硬背了,我们给书本拍照,然后看照片来回想内容!”,试想一下让你的朋友直接读 1000 页的原书,他会累晕。但让他看 100 张“缩略图”,他就轻松多了。
DeepSeek-OCR“就是拍下一张高清晰度的照片,然后再把这张图压缩为一张小小的、信息高度浓缩的“缩略图”,当我们需要信息的时候,解码器再去把这张“缩略图”,准确地复述和理解上面的内容和结构。
当然在压缩之前,DeepSeek-OCR 在对数据压缩之前也是要发挥OCR的本质的。比如下图中的这张试卷,里面有文字,有图表,有各种复杂的排版。
DeepSeek-OCR 会先把这张文档先生成为可以直接理解的markdown文档,对于里面的图片、表格再进行深度解析,最终渲染为可直接理解的内容。

传送门
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...









