Seedance 2.0是字节跳动最新发布的AI视频生成模型,它能够将文本描述或静态图片转化为高质量的电影感视频。
相比前一代1.5 Pro模型并不是简单升级,更被业界视为一次接近“导演级”控制的突破。由于生成的视频过于真实,在互联网引起的轩然大波。
过去,AI视频生成常常是“抽卡”式的运气游戏,而Seedance 2.0正试图将它变成一台精密的叙事仪器。
模型能理解复杂的长提示词,自动拆解出“全景-中景-特写”的分镜逻辑,展现类似真人导演的调度思维。通过World-MMDiT架构引入“World ID”系统,不仅锁死角色五官,还锁定身材比例、服装材质的物理属性,动作符合真实动力学。
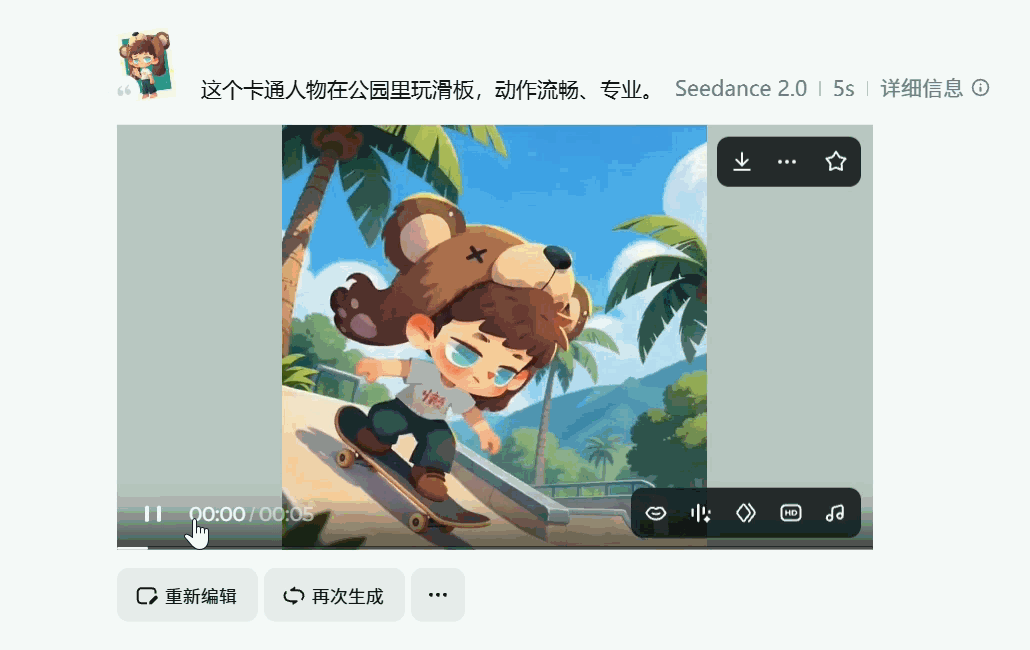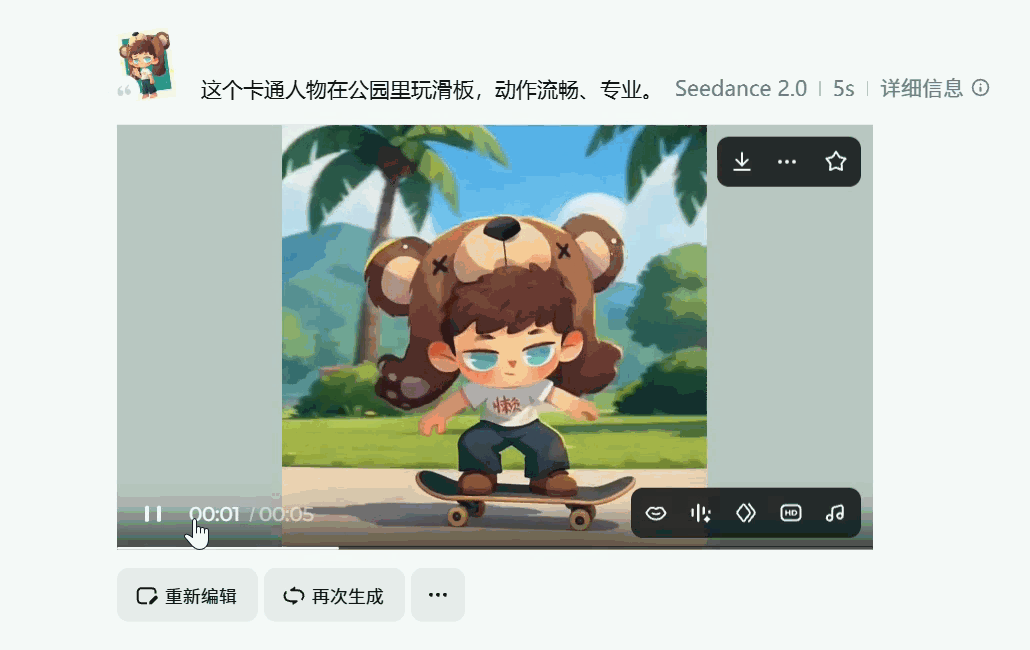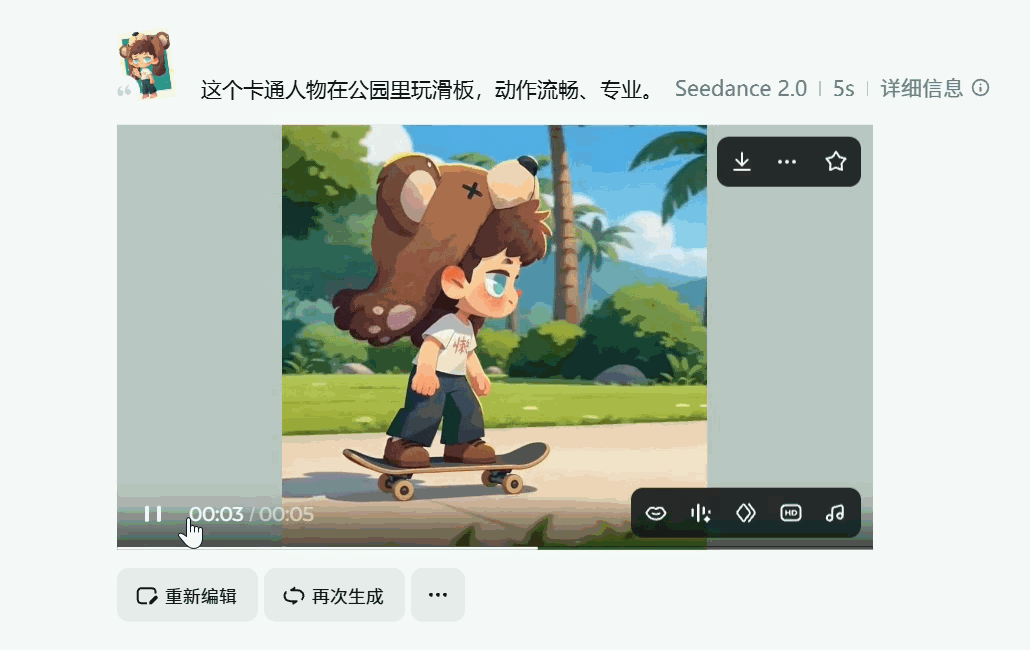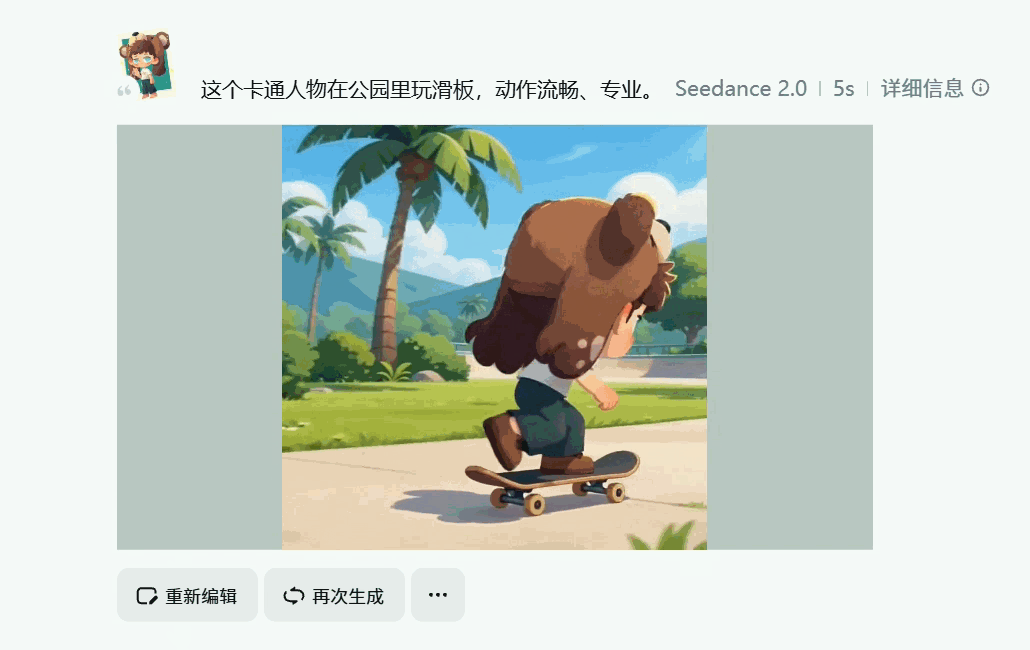
角色一致性的问题得到了有效解决,在多镜头连续生成中有效解决“脸部崩坏”问题,人物换装不再等于换脸,微表情在不同镜头中保持连贯

你敢想象,上面两个5s视频片段是我仅靠一张静态图和一句提示词就能完成的??真的太强了,关注这方便的小伙伴在各大视频平台也能刷到各种Seedance 2.0 生成逆天视频。强到很多人已经完全无法分辨是不是AI生成的了~

主要能力
- 多模态参考生成:支持同时上传最多12个参考文件,包括9张图片、3段视频(总时长≤15秒)和3段音频(总时长≤15秒),AI能自动学习并复刻画面构图、角色特征、动作风格。
- 首尾帧控制:用户可上传第一帧和最后一帧图片,AI自动生成中间过渡内容,实现精准的镜头控制和场景衔接。
- 原生音视频同步:采用双分支扩散变换器架构,在生成画面的同时原生生成音频,实现人物口型、面部表情与音频节奏精准对齐。
- 多镜头叙事:支持分镜图直接生成视频,在多个镜头中保持角色一致性、灯光连贯性和风格统一,可制作预告片、故事片等复杂叙事内容。
- 自动音频生成:内置语音、音乐、音效生成能力,可自动生成对话语音、背景音乐和环境音效
目前该模型已经上线即梦平台:https://jimeng.jianying.com/ ,5s视频需要30积分。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...